OpenAI o3 Reportedly Has an IQ of 157, Comparable to Einstein, Yet Cannot Prove It is Smarter Than Humans

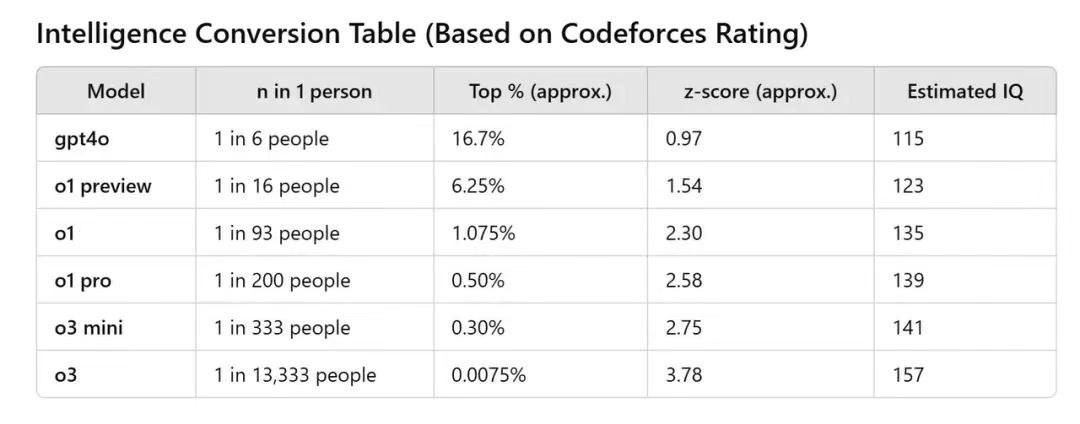
According to a widely circulated chart online, OpenAI's new model o3 scored 2727 on Codeforces, which translates to a human IQ score of 157—definitely a rare achievement. Moreover, incredibly, the AI's IQ increased by 42 points in just seven months from GPT-4o to o3.
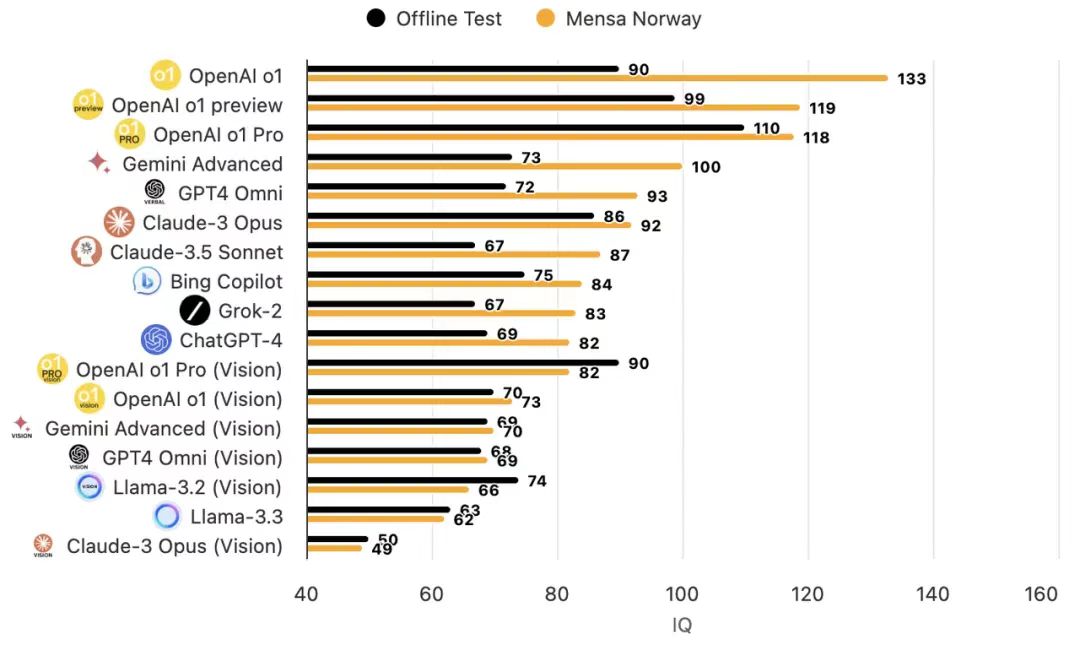
Recently, OpenAI's o1 model was highly praised for scoring as high as 133 on the Mensa IQ test, surpassing the IQ levels of most humans.
However, before lamenting humanity's defeat before AI, it’s worth pondering a more fundamental question: is it really appropriate to measure AI using a scale designed specifically for human IQ?
Smart AI Can Also Make Basic Mistakes
Any user with experience in AI can clearly conclude that while it makes sense to conduct human IQ tests on AI to a certain extent, there are significant limitations.
This limitation primarily arises from the inherent design of the tests. Traditional IQ tests are a specialized assessment system for human cognitive ability, based on uniquely human thought patterns, covering multiple dimensions such as logical reasoning, spatial awareness, and language comprehension. Obviously, using such a "human standard" to judge AI reflects a methodological bias.
Delving deeper into the differences between the human brain and AI, this bias becomes even more apparent. The human brain contains approximately 86 billion neurons, but research indicates that the number and complexity of synaptic connections may be more important than the number of neurons, with the human brain having roughly 100 trillion synaptic connections. In contrast, a 2023 study published in Nature showed that even GPT-4, with its parameter count of 1.76 trillion, has connection patterns that are far less complex than those of the human brain.
From a cognitive processing standpoint, humans think according to the path: "perceptual input → attention filtering → working memory → long-term memory storage → knowledge integration." AI systems follow the path: "data input → feature extraction → pattern matching → probability calculation → output decision," which appears similar but is fundamentally different.
Thus, despite the current AI models mimicking certain aspects of human cognitive function, they essentially remain a probability machine based on specific algorithms, with all outputs arising from programmatic processing of input data.

Recently, a research paper from Apple noted that they could find no genuine formal reasoning ability in their language models; these models behave more like they are engaged in complex pattern matching. Furthermore, this matching mechanism is extremely fragile—changing just one name could lead to a variance of about 10% in outcomes. Judging the ability to climb trees against fish would ultimately make the fish feel like a fool. Similarly, measuring AI against human standards could lead to misleading judgments.
Take GPT-4o as an example; its IQ may seem to far exceed the human average score of 100, yet it struggles to differentiate between 9.8 and 9.11, often producing "AI hallucinations." OpenAI itself has admitted in its research that GPT-4 still makes fundamental errors in handling simple numerical comparisons, indicating that AI's so-called "IQ" may be closer to mere computational ability rather than genuine intelligence. This helps explain why some extreme statements have emerged, such as claims from the CEO of DeepMind and Yann LeCun that the current IQ of AI is even lower than that of a cat—though harsh, there's an element of truth in it.
In reality, humanity has been searching for a suitable assessment system to quantify the intelligence level of AI, one that is easy to measure yet comprehensive and objective. The most well-known among these is the Turing Test. If a machine can communicate with humans without being detected, it can be deemed intelligent. However, the Turing Test has clear flaws: it focuses too much on linguistic communication skills while overlooking other crucial dimensions of intelligence.
At the same time, test results heavily rely on the personal biases and judgment capabilities of the evaluators; even a machine passing the Turing Test cannot necessarily demonstrate true understanding or consciousness; it might merely be mimicking human behavior on a superficial level.
Even the Mensa test, often regarded as an "IQ authority," cannot provide a "realistic" IQ score for AI due to its standardized nature tailored for specific age groups among humans.
So how can we visually showcase the progress of AI to the public?
The answer may lie in shifting the assessment focus toward AI's ability to solve real-world problems. Compared to IQ tests, professional evaluation standards (benchmark tests) designed specifically for particular application scenarios might be more meaningful.
From "understanding" to "regurgitating answers," why has testing AI become so difficult?
Benchmark tests can cover a wide range of topics from different dimensions. For example, GSM8K tests elementary math, while MATH focuses more on competitive exams involving algebra, geometry, and calculus. HumanEval assesses Python programming. Beyond mathematics and the sciences, AI is also tested on "reading comprehension," as demonstrated by the DROP dataset, which allows models to engage in complex reasoning based on read passages. In contrast, HellaSwag emphasizes commonsense reasoning tied to real-world scenarios.
However, benchmark tests generally face a common issue. If the testing dataset is publicly available, some models may have "previewed" these problems during training. It's similar to students completing a full set of mock exams, even true questions, before the actual exam; consequently, the final high scores might not accurately reflect their actual capabilities. In this scenario, AI's performance may merely result from simple pattern recognition and answer matching rather than genuine understanding and problem-solving. While the report card may appear excellent, it loses its reference value.

Moreover, from merely comparing scores, we see a trend toward "manipulating rankings." For example, Reflection 70B, touted as the strongest open-source large model, was found to have engaged in deceptive practices, significantly damaging the credibility of many large model rankings. Even without malpractice, as AI capabilities improve, benchmark test results often reach a state of "saturation."
As DeepMind CEO Demis Hassabis has suggested, the AI field needs better benchmark tests. While there are well-known academic benchmark tests, they have become somewhat saturated and cannot effectively distinguish subtle differences among various top models. For instance, GPT-3.5 scored 70.0 on MMLU, GPT-4 achieved 86.4, and OpenAI's o1 scored 92.3. At first glance, this seems to indicate a slowing rate of AI progress, but it actually reflects that the test has already been conquered by AI, rendering it ineffective in measuring the strength differences among models.
Like an endless cat-and-mouse game, once AI learns to cope with one assessment, the industry must seek new evaluation methods. In comparing the two common approaches, one is blind testing, where users directly vote based on preference, and the other involves continually introducing new benchmark tests. The former is exemplified by the Chatbot Arena platform, where human preferences assess models and chatbots in a competitive arena. There’s no need to provide absolute scores; users simply compare two anonymous models and vote on the better one.
The latter, recently in the spotlight, is the ARC-AGI test introduced by OpenAI. Designed by French computer scientist François Chollet, ARC-AGI specifically evaluates AI’s abstract reasoning abilities and learning efficiency on unknown tasks, widely regarded as an important standard for assessing AGI capability. These tasks are easy for humans but quite challenging for AI. ARC-AGI comprises a series of abstract visual reasoning tasks, where each task presents several inputs and corresponding output grids. Test subjects must infer the rules based on these examples and produce the correct output grids.
Under standard computational conditions, o3 scored 75.7% on ARC-AGI, while in high computational mode, it achieved a score of 87.5%. An 85% score is close to human normal levels. However, even though OpenAI o3 presented an excellent report card, it doesn’t prove that o3 has achieved AGI. François Chollet emphasized on the X platform that many ARC-AGI-1 tasks that are easy for humans remain unsolvable for the o3 model. Initial indications suggest that ARC-AGI-2 tasks are still highly challenging for this model.
This suggests that creating evaluation standards that are simple and fun for humans, yet difficult for AI, is indeed possible. When we can create such evaluation standards, we will truly possess artificial general intelligence (AGI). In short, rather than fixating on achieving high scores for AI on various human-designed tests, it may be more meaningful to think about how AI can better serve the actual needs of human society; this might be the most relevant dimension for assessing AI progress.
---